19.2.1. Deadlocks
First let's make sure that you know how
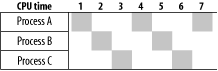
processes work with the CPU. Each process gets a tiny CPU time slice
before another process takes over. Usually operating systems use a
"round robin" technique to decide
which processes should get CPU slices and when. This decision is
based on a simple queue, with each process that needs CPU entering
the queue at the end of it. Eventually the added process moves to the
head of the queue and receives a tiny allotment of CPU time,
depending on the processor speed and implementation (think
microseconds). After this time slice, if it is still not finished,
the process moves to the end of the queue again. Figure 19-1 depicts this process. (Of course, this diagram
is a simplified one; in reality various processes have different
priorities, so one process may get more CPU time slices than others
over the same period of time.)
Figure 19-1. CPU time allocation
Now let's talk about the situation called
deadlock. If two processes simultaneously try to
acquire exclusive locks on two separate resources (databases), a
deadlock is possible. Consider this example:
sub lock_foo {
exclusive_lock('DB1');
exclusive_lock('DB2');
}
sub lock_bar {
exclusive_lock('DB2');
exclusive_lock('DB1');
}
Suppose process A calls lock_foo( ) and process B
calls lock_bar( ) at the same time. Process A
locks resource DB1 and process B locks resource
DB2. Now suppose process A needs to acquire a lock
on DB2, and process B needs a lock on
DB1. Neither of them can proceed, since they each
hold the resource needed by the other. This situation is called a
deadlock.
Using the same CPU-sharing diagram shown in Figure 19-1, let's imagine that process A
gets an exclusive lock on DB1 at time slice 1 and
process B gets an exclusive lock on DB2 at time
slice 2. Then at time slice 4, process A gets the CPU back, but it
cannot do anything because it's waiting for the lock
on DB2 to be released. The same thing happens to
process B at time slice 5. From now on, the two processes will get
the CPU, try to get the lock, fail, and wait for the next chance
indefinitely.
Deadlock wouldn't be a problem if lock_foo(
) and lock_bar( ) were atomic, which
would mean that no other process would get access to the CPU before
the whole subroutine was completed. But this never happens, because
all the running processes get access to the CPU only for a few
milliseconds or even microseconds at a time (called a time
slice). It usually takes more than one CPU time slice to
accomplish even a very simple operation.
For the same reason, this code shouldn't be relied
on:
sub get_lock {
sleep 1, until -e $lock_file;
open LF, $lock_file or die $!;
return 1;
}
The problem with this code is that the test and the action pair
aren't atomic. Even if the -e
test determines that the file doesn't exist, nothing
prevents another process from creating the file in between the
-e test and the next operation that tries to
create it. Later we will see how this problem can be resolved.