NOTE: CentOS Enterprise Linux is built from the Red Hat Enterprise Linux source code. Other than logo and name changes CentOS Enterprise Linux is compatible with the equivalent Red Hat version. This document applies equally to both Red Hat and CentOS Enterprise Linux.
Linuxtopia - CentOS Enterprise Introduzione al System Administration - Informazioni specifiche su Red Hat Enterprise Linux
Red Hat Enterprise Linux 4: Introduzione al System Administration
2.5. Informazioni specifiche su Red Hat Enterprise Linux
Red Hat Enterprise Linux presenta diversi tool per il controllo delle risorse. Anche se i suddetti tool sono pi� numerosi di quelli qui riportati, essi sono i pi� rappresentativi in termini di funzionalit�. I tool sono:
free
top (e GNOME System Monitor, una versione pi� grafica di top)
vmstat
La suite di Sysstat per i tool di controllo delle risorse
Il profiler generale del sistema di OProfile
Esaminiamoli in dettaglio.
2.5.1. free
Il comando free mostra l'utilizzo della memoria del sistema. Ecco un esempio del suo output:
La riga Mem: mostra l'utilizzo della memoria fisica, mentre Swap: mostra l'utilizzo dello spazio swap del sistema, e -/+ buffers/cache: mostra la quantit� di memoria fisica riservata ai buffer del sistema.
Poich� free per default mostra le informazioni sull'utilizzo della memoria solo una volta, esso � utile solo per un controllo breve, oppure per determinare velocemente se esiste ancora il problema relativo alla memoria stessa. Anche se free possiede l'abilit� di visualizzare ripetutamente le informazioni relative all'uso della memoria tramite la sua opzione -s, l'output continua a scorrere rendendo difficile il rilevamento di modifiche nell'utilizzo della stessa memoria.
Suggerimento
Una soluzione migliore nell'uso di free -s sarebbe quella di eseguire free usando il comando watch. Per esempio, per visualizzare l'utilizzo della memoria ogni due secondi (il valore di default per watch), usare questo comando:
watch free
Il comando watch emette il comando free ogni due secondi, eseguendo l'aggiornamento, ripulendo la schermata e scrivendo il nuovo output nella stessa posizione. Questo rende il tutto molto pi� semplice nel determinare i cambiamenti sull'utilizzo della memoria attraverso un certo periodo di tempo, in quanto watch crea una panoramica singola sull'aggiornamento senza poter eseguire uno scorrimento dei dati. � possibile controllare il ritardo tra gli aggiornamenti usando l'opzione -n, mentre � possibile evidenziare i cambiamenti utilizzando l'opzione -d come mostrato nel seguente comando:
watch -n 1 -d free
Per maggiori informazioni, consultate la pagina man di watch.
Il comando watch viene eseguito fino a quando non viene interrotto con [Ctrl]-[C]. Il comando watch � da ricordare in quanto potr� esservi molto utile in diverse situazioni.
2.5.2. top
Mentre free visualizza solo le informazioni relative alla memoria, il comando top f� un p� di tutto. Uso della CPU, statistiche sul processo, utilizzo della memoria — top controlla pi� o meno tutto. Diversamente dal comando free, il comportamento di default di top � quello di esecuzione continua; non vi � il bisogno di usare il comando watch. Eccone un esempio:
La schermata viene divisa in due sezioni. Quella superiore contiene le informazioni relative allo stato generale del sistema — l'uptime, il carico medio, i conteggi del processo, lo stato della CPU, e le statistiche sull'utilizzo sia per la memoria che per lo spazio di swap. La sezione inferiore visualizza le statistiche process-level. � possibile cambiare ci� che viene mostrato mentre top � in esecuzione. Per esempio, top per default visualizza solo i processi idle e non-idle. Per visualizzare i processi non-idle, pigiare [i]; pigiandolo una seconda volta si ritorna nella modalit� display di default.
Avvertimento
Anche se top appare come un programma di sola visualizzazione, in realt� non lo �. Questo perch� top utilizza dei comandi a caratteri singoli per eseguire diverse operazioni. Per esempio, se siete registrati come root � possibile modificare la priorit� oppure eseguire il kill di qualsiasi processo presente nel sistema. Per questo motivo, fino a quando non avete revisionato la schermata d'aiuto di top (digitate [?] per visualizzarla), � pi� sicuro digitare [q] (il quale abbandona top).
2.5.2.1. GNOME System Monitor — Un top grafico
Se vi sentite pi� a vostro agio con le graphical user interface, GNOME System Monitor potrebbe fare al caso vostro. Come top, GNOME System Monitor visualizza le informazioni relative allo stato generale del sistema, ai conteggi del processo, all'utilizzo dello spazio di swap e della memoria e alle statistiche del livello del processo.
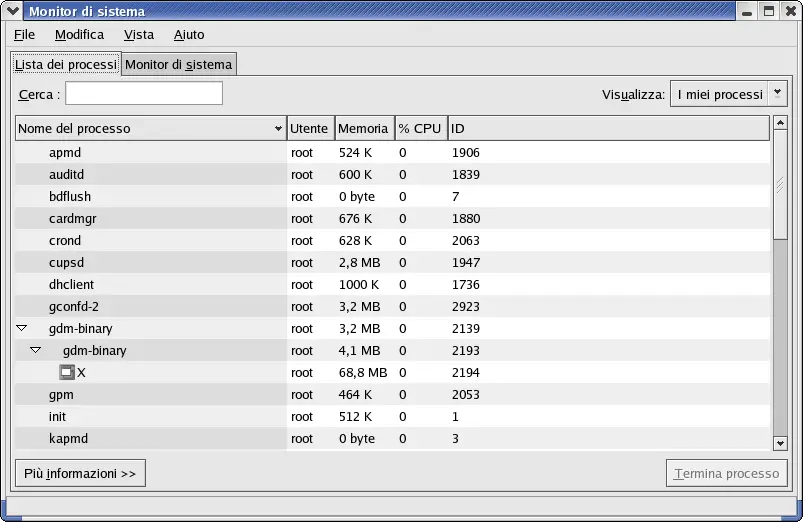
Tuttavia, GNOME System Monitor si spinge leggermente oltre, includendo anche alcune rappresentazioni grafiche della CPU, della memoria, e sull'utilizzo dello swap, insieme alla voce sull'utilizzo dello spazio tabellare del disco. Un esempio della scheramata Process Listing di GNOME System Monitor appare in Figura 2-1.
Figura 2-1. Schermata Process Listing di GNOME System Monitor
Si possono visualizzare informazioni aggiuntive per un processo specifico facendo clic sul processo desiderato e poi sul tasto More Info.
Per visualizzare la CPU, la memoria e le statistiche sull'utilizzo del disco, fate clic sul pannello Monitor del sistema.
2.5.3. vmstat
Per una conoscenza pi� approfondita sulle prestazioni del sistema, provate vmstat. Con vmstat � possibile ottenere una panoramica del processo, della memoria, di swap, I/O, del sistema, e sull'attivit� della CPU attraverso una riga composta da numeri:
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 5276 315000 130744 380184 1 1 2 24 14 50 1 1 47 0
La prima riga divide i campi in sei categorie, include il processo, la memoria, swap, I/O, il sistema e le statistiche relative alla CPU. La seconda riga identifica maggiormente i contenuti di ogni campo, facilitando un controllo rapido dei dati per specifiche statistiche.
I campi relativi al processo sono:
r — Il numero di processi eseguibili in attesa per l'accesso alla CPU
b — Il numero di processi che sono in uno stato di 'sleep'
I campi relativi alla memoria sono:
swpd — La quantit� utilizzata di memoria virtuale
free — La quantit� di memoria disponibile
buff — La quantit� di memoria usata dai buffer
cache — La quantit� di memoria utilizzata come page cache
I campi relativi allo swap sono:
si — La quantit� di memoria scambiata in entrata da un disco
so — La quantit� di memoria scambiata in uscita dal disco
I campi relativi a I/O sono:
bi — Blocchi inviati ad un dispositivo a blocco
bo— Blocchi ricevuti da un dispositivo a blocco
I campi relativi al sistema sono:
in — Il numero di interruzioni al secondo
cs — Il numero di modifiche del contesto al secondo
I campi relativi alla CPU sono:
us — La percentuale di tempo attraverso il quale la CPU ha eseguito il codice user-level
sy — La percentuale di tempo attraverso il quale la CPU ha eseguito il codice system-level
id — La percentuale di tempo nel quale la CPU � rimasta in posizione di idle
wa — attesa I/O
Quando si esegue vmstat senza opzioni viene visualizzata solo una riga. Questa riga contiene informazioni calcolate dall'ultimo avvio del sistema.
Tuttavia molti amministratori di sistema non fanno affidamento ai dati contenuti in questa riga, in quanto i dati vengono raccolti in momenti diversi. Molti amministratori invece usano l'abilit� di vmstat di visualizzare ripatutamente i dati sull'utilizzo delle risorse a determinati intervalli. Per esempio, il comando vmstat 1 visualizza una nuova riga ogni secondo, mentre il comando vmstat 1 10 visualizza una nuova riga al secondo per dieci secondi.
Se usato da un amministratore esperto, vmstat pu� essere utilizzato per determinare velocemente l'uso delle risorse e le problematiche inerenti le prestazioni. Ma per poter ottenere dettagli pi� specifici su questi argomenti, � necessario un tool diverso — un tool capace di raccogliere dati in modo pi� approfondito e di condurre analisi.
2.5.4. La suite di Sysstat per i tool di controllo delle risorse
Mentre i tool precedenti possono essere utili per ottenere informazioni pi� dettagliate sulle prestazioni del sistema in tempi molto brevi, gli stessi sono poco utili nel fornire un quadro corretto sull'utilizzo delle risorse del sistema. In aggiunta, ci sono alcuni aspetti inerenti le prestazioni del sistema che non possono essere controllati usando i suddetti tool.
Per questo motivo � necessario un tool pi� sofisticato. Sysstat rappresenta tale tool.
Sysstat contiene i seguenti tool relativi alla raccolta di I/O e delle statistiche della CPU:
iostat
Visualizza una panoramica sull'utilizzo della CPU, insieme alle statistiche I/O per una o pi� unit� disco.
mpstat
Visualizza le statistiche della CPU in modo pi� dettagliato.
Sysstat contiene anche i tool in grado di raccogliere i dati riguardanti l'uso delle risorse del sistema, e creare dei riporti giornalieri basati sui dati stessi. Questi tool sono:
sadc
Conosciuto come raccoglitore di dati sull'attivit� del sistema, sadc raccoglie le informazioni sull'utilizzo delle risorse del sistema e le scrive su di un file.
sar
Eseguendo dei rapporti dai file creati da sadc, i rapporti di sar possono essere generati in modo interattivo o scritti su di un file per analisi pi� approfondite.
Le seguenti sezioni analizzano i tool in modo pi� approfondito.
2.5.4.1. Comando iostat
Il comando iostat fornisce una panoramica della CPU e delle statistiche I/O su disco:
Sotto la prima riga (la quale contiene la versione del kernel del sistema e l'hostname, insieme con la data corrente), iostat visualizza una panoramica sull'utilizzo medio della CPU del sistema dall'ultimo riavvio. Il rapporto sull'uso della CPU include quanto segue:
La percentuale di tempo trascorso in modalit� utente (esecuzioni delle applicazioni, ecc)
Percentuale di tempo trascorso in modalit� utente (per processi che hanno modificato la loro priorit� usando nice(2))
Percentuale di tempo trascorso in modalit� kernel
Percentuale di tempo trascorso in idle
Sotto il rapporto sull'utilizzo della CPU, si trova il rapporto sull'utilizzo del dispositivo. Il suddetto rapporto contiene una riga per ogni dispositivo del disco attivo sul sistema, e include le seguenti informazioni:
La specificazione del dispositivo, visualizzato come dev<major-number>-sequence-number, dove <major-number> � il numero maggiore del dispositivo[1], e <sequence-number> � una sequenza numerica che parte da zero.
Il numero di trasferimenti (o di operazioni I/O) al secondo.
Il numero di blocchi da 512-byte letti al secondo.
Il numero di blocchi da 512-byte scritti al secondo.
Il numero totale di blocchi da 512-byte letti.
Il numero totale di blocchi da 512-byte scritti.
Questo � solo un esempio delle informazioni che si possono ottenere usando iostat. Per maggiori informazioni consultare la pagina man di iostat (1).
2.5.4.2. Comando mpstat
Il comando mpstat potrebbe apparire simile al rapporto sull'utilizzo della CPU prodotto da iostat:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:09:26 PM CPU %user %nice %system %idle intr/s
07:09:26 PM all 6.40 5.84 3.29 84.47 542.47
Con l'eccezione di una colonna aggiuntiva che mostra le interruzioni al secondo gestite dalla CPU. Tuattavia, la situazione cambia se viene utilizzata l'opzione -P ALL di mpstat:
Su sistemi multiprocessori, mpstat presenta la possibilit� per ogni CPU di essere visualizzata individualmente, permettendo di sapere come � stata usata ogni CPU.
2.5.4.3. Comando sadc
Come precedentemente osservato, il comando sadc raccoglie i dati che riguardano l'uso del sistema, e li scrive su di un file per ulteriori analisi. Per default, i dati vengono scritti sui file nella directory /var/log/sa/. I file vengono chiamati sa<dd>, dove <dd> � la data corrente espressa con due caratteri.
sadc viene eseguito normalmente dallo script sa1. Questo script viene invocato generalmente da cron tramite il file sysstat, che si trova in /etc/cron.d/. Lo script sa1 richiama sadc per un intervallo singolo di un secondo. Per default, cron esegue sa1 ogni 10 minuti, aggiungendo i dati raccolti durante ogni intervallo al file /var/log/sa/sa<dd> corrente.
2.5.4.4. Comando sar
Il comando sar fornisce i rapporti sull'utilizzo del sistema in base ai dati raccolti da sadc. Come configurato in Red Hat Enterprise Linux, sar viene eseguito automaticamente per processare i file raccolti automaticamente da sadc. I file report sono scritti su /var/log/sa/ e sono chiamati sar<dd>, dove <dd> e la rappresentazione a due caratteri della data precedente sempre a due caratteri.
sar viene eseguito normalmente dallo script sa2. Questo script viene invocato periodicamente da cron tramite il file sysstat, il quale si trova in /etc/cron.d/. Per default, cron esegue sa2 una volta al giorno alle 23:53, permettendogli di fornire un report per tutti i dati giornalieri.
2.5.4.4.1. Leggere i rapporti di sar
Il formato di un rapporto sar fornito dalla configurazione di default di Red Hat Enterprise Linux, consiste in sezioni multiple, con ogni sezione contenente un tipo specifico di dati. Poich� sadc � configurato per eseguire un intervallo di un secondo ogni dieci minuti, i report sar di default contengono dati che incrementano ogni dieci minuti, da 00:00 a 23:50 [2].
Ogni sezione del rapporto inizia con una testata che descrive i dati contenuti nella sezione stessa. La testata viene ripetuta ad intervalli regolari attraverso la sezione, rendendola pi� semplice per l'interpretazione dei dati mentre si esegue un 'paging' attraverso il rapporto. Ogni sezione termina con una riga contenente informazioni generali sui dati riportati in quella sezione.
Ecco un esempio di un rapporto della sezione sar, con i dati da 00:30 a 23:40 rimossi per ottenere spazio:
00:00:01 CPU %user %nice %system %idle
00:10:00 all 6.39 1.96 0.66 90.98
00:20:01 all 1.61 3.16 1.09 94.14
…
23:50:01 all 44.07 0.02 0.77 55.14
Average: all 5.80 4.99 2.87 86.34
In questa sezione vengono mostrate le informazioni sull'utilizzo della CPU. Questo � molto simile ai dati visualizzati da iostat.
Altre sezioni possono avere pi� di una riga per volta contenente dati, come mostrato in questa sezione generata da dati sull'utilizzo della CPU raccolti su di un sistema 'dual-processor':
Ci sono un totale di diciasette sezioni presenti nei rapporti generati dalla configurazione sar di default di Red Hat Enterprise Linux; alcuni di essi vengono affrontati nei capitoli successivi. Per maggiori informazioni sui dati contenuti in ogni sezione, consultate la pagina man di sar(1).
2.5.5. OProfile
Il profiler generale del sistema di OProfile � un tool di controllo a basso overhead. OProfile f� uso di hardware di controllo delle prestazioni del sistema[3] per determinare la natura dei problemi relativi alle prestazioni.
L'hardware di controllo delle prestazioni f� parte dello stesso processo. Prende la forma di un contatore speciale, incrementato ognivolta che si verifica un certo evento (come ad esempio se un processo non � in posizione idle oppure i dati richiesti non sono presenti nella cache). Alcuni processori presentano pi� di un contatore, e permettono di eseguire una selezione di diversi eventi per ogni contatore.
I contatori possono essere caricati con un valore iniziale e produrre una interruzione ognivolta che lo stesso contatore presenta un overflow. Caricando un contatore con diversi valori iniziali, � possibile variare la velocit� alla quale vengono prodotte le interruzioni. In questo modo � possibile controllare la velocit� campione, e cos�, il livello dei dettagli ottenuti dai dati raccolti.
Da un lato, impostando il contatore in modo da generare un overflow interrupt con ogni evento, si possono fornire dati sulla prestazione molto dettagliati (ma con un overhead elevatissimo). Al contrario impostare il contatore in modo da generare il minor numero di interruzioni possibile, si fornisce una panoramica generale delle prestazioni del sistema (con nessun overhead). Il segreto di un controllo efficace viene rappresentato dalla selezione di una velocit� campione sufficientemente alta in modo da catturare i dati necessari, ma non cos� alta da far verificare un sovraccarico del sistema con un overhead del controllo delle prestazioni.
Avvertimento
Potete configurare OProfile in modo da produrre un overhead sufficiente per rendere il sistema non pi� utilizzabile. In questo senso � necessario esercitare molta attenzione nella selezione dei valori del contatore. Per questa ragione, il comando opcontrol supporta l'opzione --list-events, la quale visualizza il tipo di evento disponibile per il processore attualmente installato, insieme con i valori del contatore minimi suggeriti.
� importante tener sempre presente il rapporto tra la velocit� campione e l'overhead quando si utilizza OProfile.
2.5.5.1. Componenti di OProfile
Oprofile consiste dei seguenti componenti:
Software di raccolta dati
Software di analisi dei dati
Software per l'interfaccia amministrativa
Il software per la raccolta dati consiste del modulo del kernel di oprofile.o, e del demone oprofiled.
Il software per l'analisi dei dati include i seguenti programmi:
op_time
Visualizza il numero e le relative percentuali di esempi presi per ogni file eseguibile
oprofpp
Visualizza il numero e le relative percentuali di esempi presi per la funzione, per le istruzioni individuali, o per output in stile gprof
op_to_source
Visualizza i codici sorgente annotati e/o dell'assembly listings
op_visualise
Visualizza graficamente i dati raccolti
Questi programmi rendono possibile visualizzare i dati raccolti in diversi modi.
Il software per l'interfaccia amministrativa controlla tutti gli aspetti di raccolta dei dati, dalla specificazione dell'evento da controllare, all'avvio e arresto della raccolta dei dati stessi. Tutto questo viene fatto usando il comando opcontrol.
2.5.5.2. Esempio della sessione di OProfile
Questa sezione mostra un controllo OProfile e una sessione per l'analisi dei dati da una configurazione iniziale ad un'analisi finale dei dati. Essa rappresenta solo una panoramica introduttiva, per maggiori informazioni consultare Red Hat Enterprise Linux System Administration Guide.
Utilizzate opcontrol per configurare il tipo di dati da raccogliere con il seguente comando:
Dirigono OProfile su di una copia del kernel corrente in esecuzione (--vmlinux=/boot/vmlinux-`uname -r`)
Specificano l'utilizzo del contatore 0 del processore e che l'evento da controllare � il periodo quando la CPU esegue le istruzioni (--ctr0-event=CPU_CLK_UNHALTED)
Specificano che OProfile deve raccogliere gli esempi ogni 6000 volte che si verifica l'evento specificato (--ctr0-count=6000)
Successivamente, controllate che il modulo del kernel di oprofile venga caricato usando il comando lsmod:
Module Size Used by Not tainted
oprofile 75616 1
…
Confermate che il file system di OProfile (posizionato in /dev/oprofile/) attraverso il comando ls /dev/oprofile/:
Successivamente, utilizzare opcontrol per iniziare la raccolta dei dati con il comando opcontrol --start:
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
Verificate che il demone oprofiled viene eseguito con il comando ps x | grep -i oprofiled:
32019 ? S 0:00 /usr/bin/oprofiled --separate-lib-samples=0 …
32021 pts/0 S 0:00 grep -i oprofiled
(La linea di comando di oprofiled visualizzata da ps � pi� lunga; tuttavia, essa � stata troncata per motivi di formattazione.)
Il sistema viene adesso monitorato, con i dati raccolti per tutti gli eseguibili presenti sul sistema. I dati vengono conservati nella directory /var/lib/oprofile/samples/. I file in questa directory seguono una convenzione di nomi molto inusuale. Ecco un esempio:
}usr}bin}less#0
Questa convenzione utilizza il percorso assoluto di ogni file contenente il codice degli eseguibili, con la barra (/) sostituita dalle parentesi graffe (}), e finendo con il simbolo cancelletto (#) seguito da un numero (in questo caso, 0.) Per questo motivo, il file usato in questo esempio rappresenta i dati raccolti mentre /usr/bin/less era in esecuzione.
Una volta raccolti i dati utilizzare uno dei tool di analisi per visualizzarli. Un lato positivo di OProfile � rappresentato dal fatto che non � necessario arrestare la raccolta dei dati prima di eseguire un'analisi. Tuttavia, � necessario aspettare la scrittura sul disco di un set di esempi, o usare il comando opcontrol --dump per forzare tale procedura.
Nel seguente esempio, op_time viene usato per visualizzare (con un ordine inverso — da un numero maggiore di esempi a quello pi� basso), gli esempi raccolti:
� buona idea quando si produce un rapporto in modo interattivo, usare less, in quanto i suddetti rapporti possono essere lunghi centinaia di righe. L'esempio riportato � stato troncato per questa ragione.
Il formato per questo rapporto in particolare � quello di una riga prodotta per ogni file eseguibile dai quali sono stati presi come esempio. Ogni riga segue questo formato:
<sample-count> rappresenta il numero di esempio raccolti
<sample-percent> rappresenta la percentuale di tutti gli esempi raccolti per questo specifico eseguibile
<unused-field> � un campo non in uso
<executable-name> rappresenta il nome del file che contiene il codice dell'eseguibile per il quale sono stati raccolti gli esempi.
Questo rapporto (fornito sulla maggior parte dei sistemi in idle) mostra che quasi la met� di tutti gli esempi sono stati presi in considerazione mentre la CPU esegue il codice all'interno dello stesso kernel. Successivamente nella riga vi � il demone per la raccolta dei dati di OProfile, seguito da diverse librerie e dal server del sistema X Window, XFree86. Vale la pena notare che per il sistema che esegue questa sessione, il valore di 6000 usato dal contatore, rappresenta il valore minimo consigliato da opcontrol --list-events. Questo significa che — almeno per questo sistema particolare — l'overhead di OProfile nel peggiore delle ipotesi consuma approssimativamente l'11% della CPU.
I numeri maggiori del dispositivo si possono trovare utilizzando ls -l, in modo da visualizzare il file del dispositivo desiderato in /dev/. Il numero maggiore in questo esempio appare dopo la specificazione del gruppo del dispositivo.
OProfile � in grado di usare anche un meccanismo di fallback (conosciuto anche come TIMER_INT), per quelle architetture del sistema che presentano delle carenze per quanto riguarda l'hardware di controllo delle prestazioni.