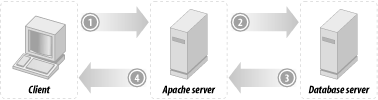
A database request from a web server to a database server running on
the same machine uses Unix sockets, not the TCP/IP sockets used when
the client submits the query from another machine. Unix sockets are
very fast, since all the communications happen within the same box,
eliminating network delays. TCP/IP socket communication totally
depends on the quality and the speed of the network that connects the
two machines.
Basically, you can have almost the same client-server speed if you
install a very fast and dedicated network between the two machines.
It might impose a cost of additional NICs, but that cost is probably
insignificant compared to the speed improvement you gain.
Even the normal network that you have would probably fit as well,
because the network delays are probably much smaller than the time it
takes to execute the query. In contrast to the previous paragraph,
you really want to test the added overhead here, since the network
can be quite slow, especially at peak hours.
How do you know what overhead is a significant one? All you have to
measure is the average time spent in the web server and the database
server. If either of the two numbers is at least 20 times bigger than
the added overhead of the network, you are all set.
To give you some numbers, if your query takes about 20 milliseconds
to process and only 1 millisecond to deliver the results,
it's good. If the delivery takes about half of the
time the processing takes, you should start considering switching to
a faster and/or dedicated network.
The consequences of a slow network can be quite bad. If the network
is slow, mod_perl processes remain open, waiting for data from the
database server, and eat even more RAM as new child processes pop up
to handle new requests. So the overall machine performance can be
worse than it was originally, when you had just a single machine for
both servers.