2.5. Informaci�n espec�fica a Red Hat Enterprise Linux
Red Hat Enterprise Linux viene con una variedad de herramientas para monitorizar recursos. Mientras que existen m�s de las que aqu� se listan, estas herramientas son representativas en t�rminos de funcionalidad. Las herramientas son:
free
top (y el Monitor del Sistema de GNOME, una versi�n de top m�s orientada a lo gr�fico)
vmstat
La suite de herramientas de supervisi�n de recursos de Sysstat
El perfilador global del sistema OProfile
Examinemos cada una con m�s detalles.
2.5.1. free
El comando free muestra la utilizaci�n de la memoria del sistema. He aqu� un ejemplo de esta salida:
La fila Mem: muestra la utilizaci�n de la memoria f�sica, mientras que la fila Swap: muestra la utilizaci�n del espacio de intercambio (swap) del sistema. La fila -/+ buffers/cache: muestra la cantidad de memoria actualmente dedicada a las memorias intermedias del sistema (buffers).
Puesto que por defecto free solamente muestra la utilizaci�n de memoria una vez, solamente es �til para una supervisi�n de corto tiempo, o para determinar r�pidamente si un problema relacionado con la memoria est� en progreso actualmente. Aunque free tiene la habilidad de mostrar repetidamente los n�meros de utilizaci�n de memoria a trav�s de su opci�n -s, la salida se desplaza, haciendo dif�cil detectar cambios en la utilizaci�n de memoria.
Sugerencia
Una mejor soluci�n que utilizar free -s, ser�a ejecutar el comando free usando el comando watch. Por ejemplo, para mostrar la utilizaci�n de memoria cada dos segundos (el intervalo de muestra predeterminado para watch), utilice este comando:
watch free
El comando watch ejecuta el comando free cada dos segundos, limpiando la pantalla para mostrar la salida actualizada y volviendo a escribir en la misma ubicaci�n de pantalla. Esto hace mucho m�s f�cil determinar c�mo cambia la utilizaci�n de memoria con el tiempo, pues no es necesario escanear cont�nuamente desplazando la salida. Puede controlar el retraso entre actualizaciones usando la opci�n -n y causar que cualquier cambio entre actualizaciones sea resaltado usando la opci�n -d, como en el comando siguiente:
watch -n 1 -d free
Para m�s informaci�n, consulte la p�gina man de watch.
El comando watch se ejecuta hasta ser interrupido con [Ctrl]-[C]. El comando watch es uno a recordar; puede ser muy �til en muchas situaciones.
2.5.2. top
Mientras que free muestra solamente informaci�n relacionada con la memoria, el comando top hace un poquito de todo. Utilizaci�n del CPU, estad�sticas de procesos, utilizaci�n de memoria — top lo monitoriza todo. Adem�s, a diferencia de free command, el comportamiento predeterminado de top es el de ejecutarse de forma cont�nua, no hay necesidad de utilizar el comando watch. He aqu� una muestra de la pantalla:
La pantalla se divide en dos secciones. La parte superior contiene informaci�n relacionada con el estatus general del sistema — tiempo ejecut�ndose, carga promedio, cuentas de procesos, estado del CPU y estad�sticas de utilizaci�n para la memoria y el espacio de intercambio. La secci�n de abajo muestra estad�sticas a nivel de procesos. Es posible cambiar lo que se muestra mientras top se ejecuta. Por ejemplo, por defecto top muestra procesos activos y ociosos. Para mostrar solamente procesos activos o que no est�n ociosos, presione [i]; otro toque lo retorna al modo de visualizaci�n predeterminado.
Atenci�n
A�n cuando top pareciera como un simple programa de visualizaci�n, este no es el caso. Esto es porque top utiliza comandos de car�cteres simples para llevar a cabo diferentes operaciones. Por ejemplo, si usted est� conectado como root, le es posible cambiar la prioridad y hasta matar cualquier proceso en su sistema. Por lo tanto, hasta que no haya revisado la pantalla de ayuda de top (escriba [?] para mostrar la ayuda), es m�s seguro solamente pulsar [q] (sale de top).
2.5.2.1. La aplicaci�n Monitor del Sistema GNOME — Un top gr�fico
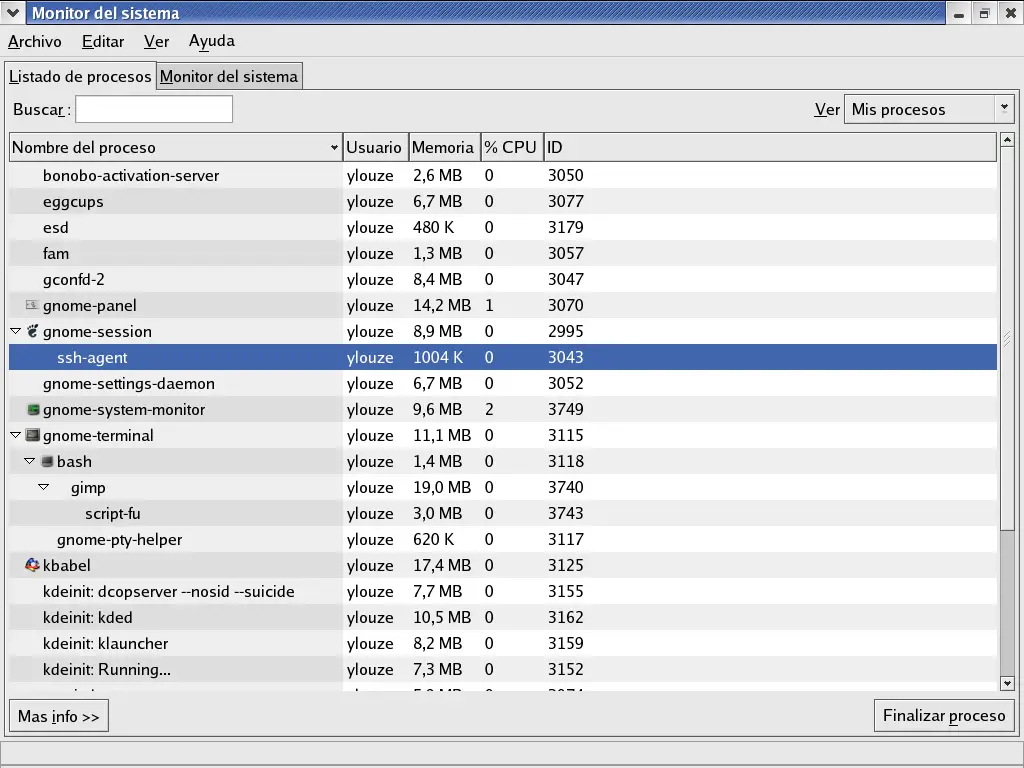
Si se siente m�s a gusto con las interfaces gr�ficas de usuarios, la aplicaci�n Monitor del Sistema GNOME puede ser m�s de su agrado. De la misma forma que top, el Monitor del Sistema GNOME muestra informaci�n relacionada al estado general del sistema, cuentas de procesos, utilizaci�n de memoria y de swap y estad�sticas a nivel de procesos.
Sin embargo, el Monitor del Sistema GNOME va un paso m�s all� incluyendo tambi�n representaciones gr�ficas del CPU, utilizaci�n de memoria y de intercambio, junto con un listado tabular de la utilizaci�n del espacio en disco. Un ejemplo del Listado de procesos del Monitor del Sistema GNOME aparece en la Figura 2-1.
Figura 2-1. La pantalla Listado de procesos del Monitor del sistema
Se puede mostrar informaci�n adicional sobre un proceso espec�fico pulsando primero en el proceso deseado y luego pulsando en el bot�n M�s Info.
Para mostrar las estad�sticas de uso de memoria, CPU y uso del disco, pulse la pesta�a Monitor del sistema.
2.5.3. vmstat
Para una comprensi�n m�s concisa del rendimiento del sistema, intente con vmstat. Con vmstat, es posible obtener una vista general de los procesos, memoria, swap, E/S, sistema y actividad de CPU en una l�nea de n�meros:
procs memory swap io system cpu
r b swpd free buff cache si so bi bo in cs us sy id wa
0 0 5276 315000 130744 380184 1 1 2 24 14 50 1 1 47 0
La primera l�nea divide los campos en seis categor�as, incluyendo procesos, memoria, swap, E/S, sistema y estad�sticas relacionadas al CPU. La segunda l�nea identifica a�n m�s los contenidos de cada campo, haciendo m�s f�cil escanear datos para ver estad�sticas espec�ficas.
Los campos relacionados a procesos son:
r — El n�mero de procesos ejecutables esperando para acceder al CPU
b — El n�mero de procesos en un estado dormido cont�nuo
Los campos relacionados a la memoria son:
swpd — La cantidad de memoria utilizada
free — La cantidad de memoria libre
buff — La cantidad de memoria utilizada por las memorias intermedias
cache — La cantidad de memoria utilizada como cach� de p�ginas
Los campos relacionados a swap son:
si — La cantidad de memoria intercambiada desde el disco
so — La cantidad de memoria intercambiada hacia el disco
Los campos relacionados con E/S son:
bi — Los bloques enviados a un dispositivo de bloques
bo — Los bloques recibidos desde un dispositivo de bloques
Los campos relacionados al sistema son:
in — El n�mero de interrupciones por segundo
cs — El n�mero de cambios de contexto por segundo
Los campos relacionados al CPU son:
us — El porcentaje de tiempo que el CPU ejecut� c�digo de nivel del usuario
sy — El porcentaje de tiempo que el CPU ejecut� c�digo de nivel del sistema
id — El porcentaje de tiempo que el CPU estaba desocupado
wa — Esperas de E/S
Cuando se ejecuta vmstat sin opciones, solamente se muestra una l�nea. Esta l�nea contiene promedios, calculados desde la �ltima vez que se arranc� el sistema.
Sin embargo, la mayor�a de los administradores de sistemas no conf�an en los datos en esta l�nea, pues los tiempos en que fueron recopilados var�an. En su lugar, la mayor�a de los administradores tomas ventaja de la habilidad de vmstat de mostrar repetidamente datos de la utilizaci�n de recursos en intervalos establecidos. Por ejemplo, el comando vmstat 1 muestra una nueva l�nea de utilizaci�n de datos cada segundo, mientras que el comando vmstat 1 10, muestra una nueva l�nea por segundo, pero s�lo por los pr�ximos 10 segundos.
En manos de un administrador experimentado, vmstat puede ser usado para determinar r�pidamente la utilizaci�n de recursos y problemas de rendimiento. Pero para obtener mayor conocimiento en estos problemas, se requiere un tipo de herramienta diferente — una herramienta capaz recolectar y analizar datos en mas detalles.
2.5.4. Las herramientas para monitorizar recursos de la suite Sysstat
Mientras que las herramientas anteriores pueden ser de ayuda para ganar mayor conocimiento sobre el rendimiento del sistema en per�odos muy cortos, son de poca utilidad en proporcionar m�s all� de una instant�nea de la utilizaci�n de recursos del sistema. Adem�s, hay aspectos del rendimiento del sistema que no se pueden monitorizar f�cilmente usando tales herramientas tan simpl�sticas.
Por lo tanto, se requiere una herramienta m�s sofisticada. Sysstat es la herramienta.
Sysstat contiene las siguientes herramientas relacionadas con reunir estad�sticas de E/S y CPU:
iostat
Muestra una descripci�n general de la utilizaci�n del CPU, junto con las estad�sticas de E/S para uno o m�s unidades de disco.
mpstat
Muestra estad�sticas de CPU m�s complejas.
Sysstat tambi�n contiene herramientas para reunir datos de utilizaci�n de los recursos y crear informes diarios basados en esos datos. Estas herramientas son:
sadc
Conocida como el coleccionador de datos de actividad del sistema, sadc reune informaci�n sobre la utilizaci�n de recursos y la escribe a un archivo.
sar
Los informes sar, producidos a partir de los archivos creados por sadc, se pueden generar interactivamente o se pueden escribir a un archivo para un an�lisis m�s intensivo.
Las secciones siguientes exploran cada una de estas herramientas con m�s detalles.
2.5.4.1. El comando iostat
El comando iostat en su forma m�s b�sica proporciona una descripci�n general de las estad�sticas del CPU y E/S de disco:
Debajo de la primera l�nea (la cual contiene la versi�n del kernel del sistema y el nombre del host, junto con la fecha actual), iostat muestra una vista general de la utilizaci�n promedio del CPU desde el �ltimo arranque. El informe de utilizaci�n del CPU incluye los porcentajes siguientes:
Porcentaje de tiempo en modo usuario (ejecutando aplicaciones, etc.)
Porcentaje de tiempo en modo usuario (para procesos que han alterado su prioridad de planificaci�n usando nice(2))
Porcentaje de tiempo en modo kernel
Porcentaje de tiempo ocioso
Debajo del informe de utilizaci�n del CPU est� el informe de utilizaci�n de dispositivos. Este informe contiene una l�nea para cada dispositivo en el sistema e incluye la informaci�n siguiente:
La especificaci�n de dispositivos, mostrada como dev<major-number>-sequence-number, donde <major-number> es el n�mero principal ("major") del dispositivo[1] y <sequence-number> es un n�mero secuencial comenzando desde cero.
El n�mero de transferencias (u operaciones de E/S) por segundo.
El n�mero de bloques de 512 bytes le�dos por segundo.
El n�mero de bloques de 512 bytes escritos por segundo.
El n�mero total de bloques de 512 bytes le�dos.
El n�mero total de bloques de 512 bytes escritos.
Esto es solamente un muestra de la informaci�n que se puede obtener usando iostat. Para m�s informaci�n, consulte la p�gina man de iostat(1).
2.5.4.2. El comando mpstat
El comando mpstat aparece primero sin diferencias con el informe de utilizaci�n de CPU producido por iostat:
Linux 2.4.20-1.1931.2.231.2.10.ent (pigdog.example.com) 07/11/2003
07:09:26 PM CPU %user %nice %system %idle intr/s
07:09:26 PM all 6.40 5.84 3.29 84.47 542.47
Con la excepci�n de una columna adicional mostrando las interrupciones por segundo manejadas por el CPU, no hay diferencia real. Sin embargo, la situaci�n cambia si se utiliza la opci�n de mpstat, -P ALL.
En sistemas multiproceso, mpstat permite desplegar de forma individual la utilizaci�n de cada CPU, haciendo posible determinar que tan efectivamente se utiliza cada CPU.
2.5.4.3. El comando sadc
Como se estableci� anteriormente, el comando sadc reune los datos de utilizaci�n del sistema y los escribe a un archivo para su an�lisis posterior. Por defecto, los datos son escritos a archivos en el directorio /var/log/sa/. Los archivos son llamados sa<dd>, donde <dd> es la fecha actual de dos d�gitos.
sadc normalmente es ejecutado por el script sa1. cron invoca peri�dicamente este script a trav�s del archivo sysstat, el cual est� ubicado en /etc/cron.d/. El script sa1 invoca sadc por un intervalo �nico de un segundo. Por defecto, cron ejecuta sa1 cada 10 minutos, a�adiendo los datos reunidos durante cada intervalo al archivo actual /var/log/sa/sa<dd>.
2.5.4.4. El comando sar
El comando sar produce informes de utilizaci�n del sistema basado en los datos reunidos por sadc. De acuerdo a la configuraci�n en Red Hat Enterprise Linux, sar es ejecutado autom�ticamente para procesar los archivos reunidos autom�ticamente por sadc. Los archivos de informes se escriben a /var/log/sa/ y son nombrados sar<dd>, donde <dd> son las representaciones de dos d�gitos de la fecha del d�a anterior.
Normalmente, sar es ejecutado por el script sa2. Peri�dicamente cron invoca este script a trav�s del archivo sysstat, el cual se ubica en /etc/cron.d/. Por defecto, cron ejecuta a sa2 una vez al d�a, a las 23:53, permitiendo as� producir un informe para los datos del d�a completo.
2.5.4.4.1. Lectura de informes sar
El formato de un informe sar generado por la configuraci�n predeterminada de Red Hat Enterprise Linux consiste de m�ltiples secciones, con cada secci�n conteniendo un tipo de datos espec�fico, ordenados por hora del d�a en que los datos fueron reunidos. Puesto que sadc est� configurado para ejecutar un intervalo de un segundo cada 10 minutos, el informe sar predeterminado contiene datos en incrementos de 10 minutos, desde las 00:00 hasta las 23:50[2].
Cada secci�n del informe comienza con un encabezado describiendo los datos contenidos en la secci�n. El encabezado se repite a intervalos regulares a lo largo de la secci�n, haciendo m�s f�cil interpretar los datos mientras se hojea el informe. Cada secci�n termina con una l�nea conteniendo el promedio de datos informados en la secci�n.
He aqu� una secci�n de ejemplo de un informe sar, con los datos desde 00:30 hasta 23:40 eliminados para ahorrar espacio:
00:00:01 CPU %user %nice %system %idle
00:10:00 all 6.39 1.96 0.66 90.98
00:20:01 all 1.61 3.16 1.09 94.14
…
23:50:01 all 44.07 0.02 0.77 55.14
Average: all 5.80 4.99 2.87 86.34
En esta secci�n, se muestra la informaci�n de utilizaci�n del CPU. Esto es muy similar a los datos mostrados por iostat.
Otras secciones pueden tener m�s de una l�nea necesaria para datos, como se muestra en esta secci�n generada a partir de los datos de utilizaci�n del CPU en un sistema con dos procesadores:
Hay un total de diecisiete secciones diferentes presente en los reportes generados por la configuraci�n predeterminada de Red Hat Enterprise Linux para sar; se exploran algunas en los siguientes cap�tulos. Para m�s informaci�n sobre los datos contenidos en cada secci�n, consulte la p�gina del manual de sar(1).
2.5.5. OProfile
El perfilador global del sistema OProfile, es una herramienta de supervisi�n con poca sobrecarga. Oprofile aprovecha el hardware de monitorizaci�n del rendimiento del procesador[3] para determinar la naturaleza de los problemas relacionados al rendimiento.
El hardware de monitorizaci�n del rendimiento es parte del procesador mismo. Toma la forma de un contador especial, incrementado cada vez que ocurre un determinado evento (tal como que el procesador no est� ocioso o que los datos requeridos no se encuentren en cach�). Algunos procesadores tienen m�s de uno de tales contadores y permiten la selecci�n de tipos diferentes para cada contador.
Los contadores se pueden cargar con un valor inicial y producir una interrupci�n cuando se desborde el contador. Al cargar el contador con valores iniciales diferentes, es posible variar las tasas en las que ocurre la interrupci�n. De esta forma es posible controlar la tasa de muestra y, por lo tanto, el nivel de detalle obtenido desde los datos reunidos.
En un extremo, al establecer el contador de manera que genere una interrupci�n por desborde con cada evento, proporciona datos de rendimiento en extremo detalle (pero con una sobrecarga excesiva). En el otro extremo, al configurar el contador para que genere tan pocas interrupciones como sea posible solamente proporciona la vista m�s general del rendimiento del sistema (practicamente sin ninguna sobrecarga). El secreto para una monitorizaci�n efectiva es la selecci�n de una tasa de muestra lo suficientemente alta como para capturar los datos requeridos, pero no tan alta como para sobrecargar el sistema con la monitorizaci�n.
Atenci�n
Puede configurar OProfile para que produzca tanta sobrecarga como para dejar el sistema inutilizable. Por lo tanto, debe tener cuidado cuando seleccione los valores de contador. Por esta raz�n, el comando opcontrol soporta la opci�n --list-events, el cual despliega los diferentes tipos de eventos disponibles para el procesador instalado actualmente, junto con los valores de contador m�nimos sugeridos para cada uno.
Es importante tener en mente el costo de la relaci�n entre la tasa de muestra y la sobrecarga cuando se utiliza OProfile.
2.5.5.1. Componentes de OProfile
OProfile consiste de los siguientes componentes:
Software de recolecci�n de datos
Software de an�lisis de datos
Software de interfaz administrativa
El software de colecci�n de datos consiste del m�dulo del kernel oprofile.o y el demonio oprofiled.
El software de an�lisis de datos incluye los programas siguientes:
op_time
Muestra el n�mero y los porcentajes relativos de las muestras tomadas por cada archivo ejecutable
oprofpp
Muestra el n�mero y el porcentaje relativo de muestras tomadas por funci�n, instrucci�n individual o en salida estilo gprof.
op_to_source
Muestra c�digo fuente anotado y o listados de acumulaci�n
op_visualise
Presenta los datos reunidos de forma gr�fica
Estos programas hacen posible mostrar los datos reunidos en diferentes formas.
El software de interfaz administrativa controla todos los aspectos de la colecci�n de datos, desde especificar cuales eventos espec�ficos ser�n monitorizados hasta arrancar y detener la colecci�n de datos mismos. Esto se hace usando el comando opcontrol.
2.5.5.2. Un ejemplo de sesi�n de OProfile
Esta secci�n muestra una sesi�n de OProfile supervisando y analizando datos desde la configuraci�n inicial hasta el an�lisis final de los datos. Es solamente un visi�n general introductoria; para informaci�n m�s detallada, consulte el Manual de administraci�n del sistema de Red Hat Enterprise Linux.
Utilice opcontrol para configurar el tipo de datos a ser reunido con el comando siguiente:
Dirigir OProfile a una copia del kernel ejecut�ndose actualmente (--vmlinux=/boot/vmlinux-`uname -r`)
Especificar que se utilizar� el contador 0 del procesador y que el evento a supervisar es el tiempo cuando el CPU est� ejecutando instrucciones (--ctr0-event=CPU_CLK_UNHALTED)
Especificar que OProfile va a reunir muestras cada 6000th veces que el evento ocurra (--ctr0-count=6000)
Luego, verifique que el m�dulo del kernel oprofile est� cargado usando el comando lsmod:
Module Size Used by Not tainted
oprofile 75616 1
…
Confirme que el sistema de archivos de OProfile (ubicado en /dev/oprofile/) est� montado con el comando ls /dev/oprofile/:
Luego, utilice opcontrol para arrancar la recolecci�n de datos con el comando opcontrol --start:
Using log file /var/lib/oprofile/oprofiled.log
Daemon started.
Profiler running.
Verifique que el demonio oprofiled est� ejecut�ndose con el comando ps x | grep -i oprofiled:
32019 ? S 0:00 /usr/bin/oprofiled --separate-lib-samples=0 …
32021 pts/0 S 0:00 grep -i oprofiled
(La l�nea de comandos real de oprofiled mostrada por ps es mucho m�s larga; sin embargo, la hemos truncado para prop�sitos de formato.)
Ahora se est� monitorizando el sistema, con todos los datos reunidos por todos los ejecutables en el sistema. Los datos son almacenados en el directorio /var/lib/oprofile/samples/. Los archivos en este directorio siguen una convenci�n de nombres un poco inusual. He aqu� un ejemplo:
}usr}bin}less#0
La convenci�n de nombres utiliza la ruta absoluta de cada archivo conteniendo c�digo ejecutable, reemplazando los car�cteres de barra obl�cua (/) por llaves (}), y termin�ndose con una almohadilla (#) seguido de un n�mero (en este caso, 0.) Por lo tanto, el archivo utilizado en este ejemplo representa los datos reunidos mientras se estaba ejecutando /usr/bin/less.
Una vez que los datos son reunidos, utilice alguna de las herramientas de an�lisis de datos para desplegarlos. Una de las buenas funcionalidades de OProfile es que no es necesario detener la recolecci�n de datos antes de efectuar el an�lisis de datos. Sin embargo, debe esperar al menos a que se escriban un conjunto de muestras al disco, o utilice el comando opcontrol --dump para forzar las muestras al disco.
En el ejemplo siguiente, op_time se utiliza para mostrar (en orden inverso — desde el n�mero m�s alto de muestras hasta el m�s bajo) las muestras que se han reunido:
Es una buena idea el uso de less cuando se genera un informe interactivamente, ya que los informes pueden ser de cientos de l�neas. El ejemplo dado aqu� se ha truncado por este motivo.
El formato para este informe en particular es que se produce una l�nea para cada archivo ejecutable para los que se tomaron muestras. Cada l�nea sigue el formato siguiente:
<sample-count> representa el n�mero de muestras reunidas
<sample-percent> representa el porcentaje de todas las muestras reunidas para este ejecutable en particular.
<unused-field> es un campo que no se utiliza
<executable-name> representa el nombre del archivo que contiene el c�digo del ejecutable para el que se reunen las muestras.
Este reporte (producido en la mayor�a de los sistemas ociosos) muestra que casi la mitad de todas las muestras fueron tomadas mientras que el CPU estaba ejecutando c�digo dentro del kernel mismo. Luego en la l�nea estaba el demonio de colecci�n de datos de OProfile, seguido por una variedad de bibliotecas y el servidor del sistema X Window, XFree86. Es de utilidad tomar en cuenta que para el sistema ejecutando la sesi�n de muestra, el valor del contador usado de 6000 representa el valor m�nimo recomendado por opcontrol --list-events. Esto significa que — al menos para este sistema en particular — la sobrecarga de OProfile en su punto m�s alto, consume aproximadamente 11% del CPU.
Los n�meros "major" de dispositivos se pueden encontrar usando ls -l para mostrar el archivo de dispositivo deseado en /dev/. El n�mero major aparece despu�s de la especificaci�n del grupo del dispositivo.
OProfile tambi�n puede utilizar un mecanismo de fallback (conocido como TIMER_INT) para aquellas arquitecturas que no tienen el hardware de monitorizaci�n de rendimiento.