16.2.1. MySQL Cluster Nodes, Node Groups, Replicas, and Partitions
This section discusses the manner in which MySQL Cluster divides
and duplicates data for storage.
Central to an understanding of this topic are the following
concepts, listed here with brief definitions:
-
(Data) Node: An
ndbd process, which stores a
replica —that is, a copy of the
partition (see below) assigned to the
node group of which the node is a member.
Each data node is usually located on a separate computer.
However, it is also possible to host multiple data nodes on
a single computer having more than one processor. In such
cases, it is feasible to run one instance of
ndbd per physical CPU. (Note that a
processor with multiple cores is still a single processor.)
It is common for the terms “node” and
“data node” to be used interchangeably when
referring to an ndbd process; where
mentioned, management nodes (ndb_mgmd
processes) and SQL nodes (mysqld
processes) are specified as such in this discussion.
-
Node Group: A node group
consists of one or more nodes, and stores a partition, or
set of replicas (see next item).
Note: Currently, all node
groups in a cluster must have the same number of nodes.
Partition: This is a
portion of the data stored by the cluster. There are as many
cluster partitions as node groups participating in the
cluster, and each node group is responible for keeping at
least one copy of the partition assigned to it (that is, at
least one replica) available to the cluster.
Replica: This is a copy of
a cluster partition. Each node in a node group stores a
replica. Also sometimes known as a partition
replica.
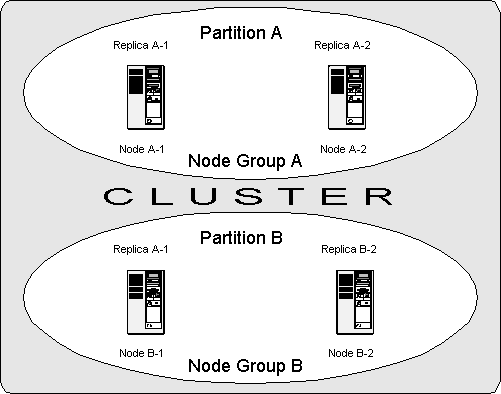
The following diagram illustrates a MySQL Cluster with four data
nodes, arranged in two node groups of two nodes each. Note that
no nodes other than data nodes are shown here, although a
working cluster requires an ndb_mgm process
for cluster management and at least one SQL node to access the
data stored by the cluster.
The data stored by the cluster is divided into two partitions,
labeled A and
B in the diagram. Each
partition is stored — in multiple copies — on a node
group. The data making up Partition
A is stored on Node
A-1, and this data is identical
to that stored by Node A-2. The
data stored by Nodes B-1 and
B-2 is also the same —
these two nodes store identical copies of the data making up
Partition B.
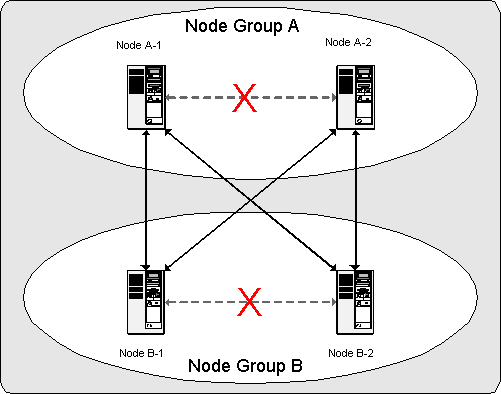
What this means so far as the continued operation of a MySQL
Cluster is this: so long as each node group participating in the
cluster has at least one “live” node, the cluster
has a complete copy of all data and remains viable. This is
illustrated in the next diagram.
In this example, where the cluster consists of two node groups
of two nodes each, any combination of at least one node in Node
Group A and at least one node
in Node Group B is sufficient
to keep the cluster “alive” (indicated by arrows in
the diagram). However, if both nodes from either node group
fail, the remaining two nodes are not sufficient (shown by
arrows marked out with an X);
in either case, the cluster has lost an entire partition and so
can no longer provide access to a complete set of all cluster
data.