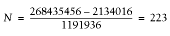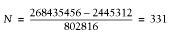Example 10-12. realloc.pl
use Devel::Peek;
foo( ) for 1..2;
sub foo {
my $sv;
Dump $sv;
print "----\n";
$sv = 'x' x 100_000;
$sv = "";
Dump $sv;
print "\n\n";
}
The code starts by loading the Devel::Peek module
and calling the function foo( ) twice in the
for loop.
The foo( ) function declares a lexically scoped
variable, $sv (scalar value). Then it dumps the
$sv data structure and prints a separator, assigns
a string of 100,000 x characters to
$sv, assigns it to an empty string, and prints the
$sv data structure again. At the end, a separator
of two empty lines is printed.
Let's observe the output generated by this code:
SV = NULL(0x0) at 0x80787c0
REFCNT = 1
FLAGS = (PADBUSY,PADMY)
----
SV = PV(0x804c6c8) at 0x80787c0
REFCNT = 1
FLAGS = (PADBUSY,PADMY,POK,pPOK)
PV = 0x8099d98 ""\0
CUR = 0
LEN = 100001
SV = PV(0x804c6c8) at 0x80787c0
REFCNT = 1
FLAGS = (PADBUSY,PADMY)
PV = 0x8099d98 ""\0
CUR = 0
LEN = 100001
----
SV = PV(0x804c6c8) at 0x80787c0
REFCNT = 1
FLAGS = (PADBUSY,PADMY,POK,pPOK)
PV = 0x8099d98 ""\0
CUR = 0
LEN = 100001
In this output, we are interested in the values of
PV—the memory address of the string value,
and LEN—the length of the allocated memory.
When foo( ) is called for the first time and the
$sv data structure is dumped for the first time,
we can see that no data has yet been assigned to it. The second time
the $sv data structure is dumped, we can see that
while $sv contains an empty string, its data
structure still kept all the memory allocated for the long string.
Notice that $sv is declared with my(
), so at the end of the function foo( )
it goes out of scope (i.e., it is destroyed). To our surprise, when
we observe the output from the second call to foo(
), we discover that when $sv is declared
at the beginning of foo( ), it reuses the data
structure from the previously destroyed $sv
variable—the PV field contains the same
memory address and the LEN field is still 100,101
characters long.
If we had asked for a longer memory chunk during the second
invocation, Perl would have called realloc( ) and
a new chunk of memory would have been allocated.
Therefore, if you have some kind of buffering variable that will grow
over the processes life, you may want to preallocate the memory for
this variable. For example, if you know a variable
$Book::Buffer::buffer may grow to the size of
100,000 characters, you can preallocate the memory in the following
way:
package Book::Buffer;
my $buffer;
sub prealloc { $buffer = ' ' x 100_000; $buffer = ""; 0;}
# ...
1;
You should load this module during the
PerlChildInitHandler. In
startup.pl, insert:
use Book::Buffer;
Apache->push_handlers(PerlChildInitHandler => \&Book::Buffer::prealloc);
so each child will allocate its own memory for the variable. When
$Book::Buffer::bufferstarts growing at runtime,
no time will be wasted on memory reallocation as long as the
preallocated memory is sufficient.