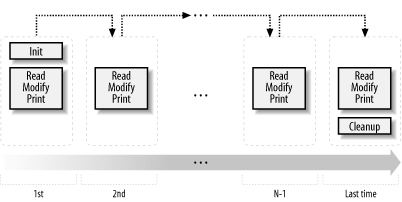
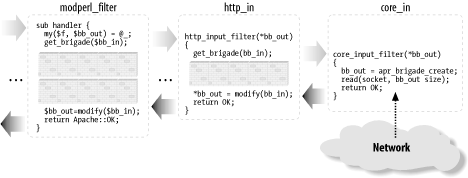
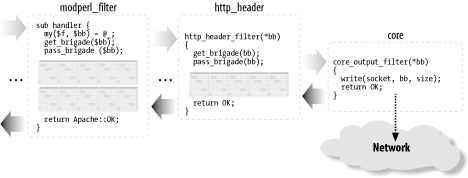
-
Create a new, empty bucket brigade, $ctx_bb, pass
it to the upstream filter via get_brigade( ), and
wait for this call to return. When it returns,
$ctx_bb is populated with buckets. Now the filter
should move the bucket from $ctx_bb to
$bb, on the way modifying the buckets if needed.
Once the buckets are moved, and the filter returns, the downstream
filter will receive the populated bucket brigade.
-
Pass $bb to get_brigade( ) to
the upstream filter, so it will be populated with buckets. Once
get_brigade( ) returns, the filter can go through
the buckets and modify them in place, or it can do nothing and just
return (in which case, the downstream filter will receive the bucket
brigade unmodified).
Both techniques allow addition and removal of buckets, alhough the
second technique is more efficient since it doesn't
have the overhead of creating the new brigade and moving the bucket
from one brigade to another. In this example we have chosen to use
the second technique; in the next example we will see the first
technique.
Our filter has to perform the substitution of only one HTTP header
(which normally resides in one bucket), so we have to make sure that
no other data gets mangled (e.g., there could be
POST ed data that may match
/^GET/ in one of the buckets). We use
$filter->ctx as a flag here. When
it's undefined, the filter knows that it
hasn't done the required substitution; once it
completes the job, it sets the context to 1.
To optimize the speed, the filter immediately returns
Apache::DECLINED when it's
invoked after the substitution job has been done:
return Apache::DECLINED if $filter->ctx;
mod_perl then calls get_brigade( ) internally,
which passes the bucket brigade to the downstream filter.
Alternatively, the filter could do:
my $rv = $filter->next->get_brigade($bb, $mode, $block, $readbytes);
return $rv unless $rv = = APR::SUCCESS;
return Apache::OK if $filter->ctx;
but this is a bit less efficient.
If the job hasn't yet been done, the filter calls
get_brigade( ), which populates the
$bb bucket brigade. Next, the filter steps through
the buckets, looking for the bucket that matches the regex
/^GET/. If it finds it, a new bucket is created
with the modified data s/^GET/HEAD/, and that
bucket is inserted in place of the old bucket. In our example, we
insert the new bucket after the bucket that we have just modified and
immediately remove the bucket that we don't need any
more:
$b->insert_after($bn);
$b->remove; # no longer needed
Finally, we set the context to 1, so we know not
to apply the substitution on the following data and break from the
for loop.
The handler returns Apache::OK, indicating that
everything was fine. The downstream filter will receive the bucket
brigade with one bucket modified.
Example 25-6. Book/RequestType.pm
package Book::RequestType;
use strict;
use warnings;
use Apache::RequestIO ( );
use Apache::RequestRec ( );
use Apache::Response ( );
use Apache::Const -compile => 'OK';
sub handler {
my $r = shift;
$r->content_type('text/plain');
my $response = "the request type was " . $r->method;
$r->set_content_length(length $response);
$r->print($response);
Apache::OK;
}
1;
This handler returns to the client the request type it has issued. In
the case of the HEAD request, Apache will discard
the response body, but it will still set the correct
Content-Length header, which will be 24 in case of
a GET request and 25 for HEAD.
Therefore, if this response handler is configured as:
Listen 8005
<VirtualHost _default_:8005>
<Location />
SetHandler modperl
PerlResponseHandler +Book::RequestType
</Location>
</VirtualHost>
and a GET request is issued to
/:
panic% perl -MLWP::UserAgent -le \
'$r = LWP::UserAgent->new( )->get("https://localhost:8005/"); \
print $r->headers->content_length . ": ". $r->content'
24: the request type was GET
the response's body is:
the request type was GET
and the Content-Length header is set to 24.
However, if we enable the
Book::InputFilterGET2HEAD input connection filter:
Listen 8005
<VirtualHost _default_:8005>
PerlInputFilterHandler +Book::InputFilterGET2HEAD
<Location />
SetHandler modperl
PerlResponseHandler +Book::RequestType
</Location>
</VirtualHost>
and issue the same GET request, we get only:
25:
which means that the body was discarded by Apache, because our filter
turned the GET request into a
HEAD request. If Apache wasn't
discarding the body of responses to HEAD requests,
the response would be:
the request type was HEAD