modules to filter both the request and the
response. Now one module can pipe its output to another module as if
it were being sent directly from the TCP stream. The same mechanism
works with the generated response.
With I/O filtering in place, simple filters (e.g., data compression
and decompression) can easily be implemented, and complex filters
(e.g., SSL) can now be implemented without needing to modify the the
server code (unlike with Apache 1.3).
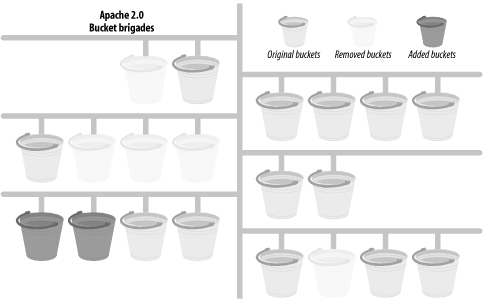
To make the filtering mechanism efficient and avoid unnecessary
copying, the bucket brigades model was used, as
follows.
A bucket represents a chunk of data. Buckets linked together comprise
a brigade. Each bucket in a brigade can be modified, removed, and
replaced with another bucket. The goal is to minimize the data
copying where possible. Buckets come in different types: files, data
blocks, end-of-stream indicators, pools, etc. You
don't need to know anything about the internal
representation of a bucket in order to manipulate it.
The stream of data is represented by bucket brigades. When a filter
is called, it gets passed the brigade that was the output of the
previous filter. This brigade is then manipulated by the filter
(e.g., by modifying some buckets) and passed to the next filter in
the stack.